Hyperscale Compliance Architecture
The Hyperscale Compliance architecture comprises four components mainly; Controller Service, Unload Service, Masking Service, and Load Service.
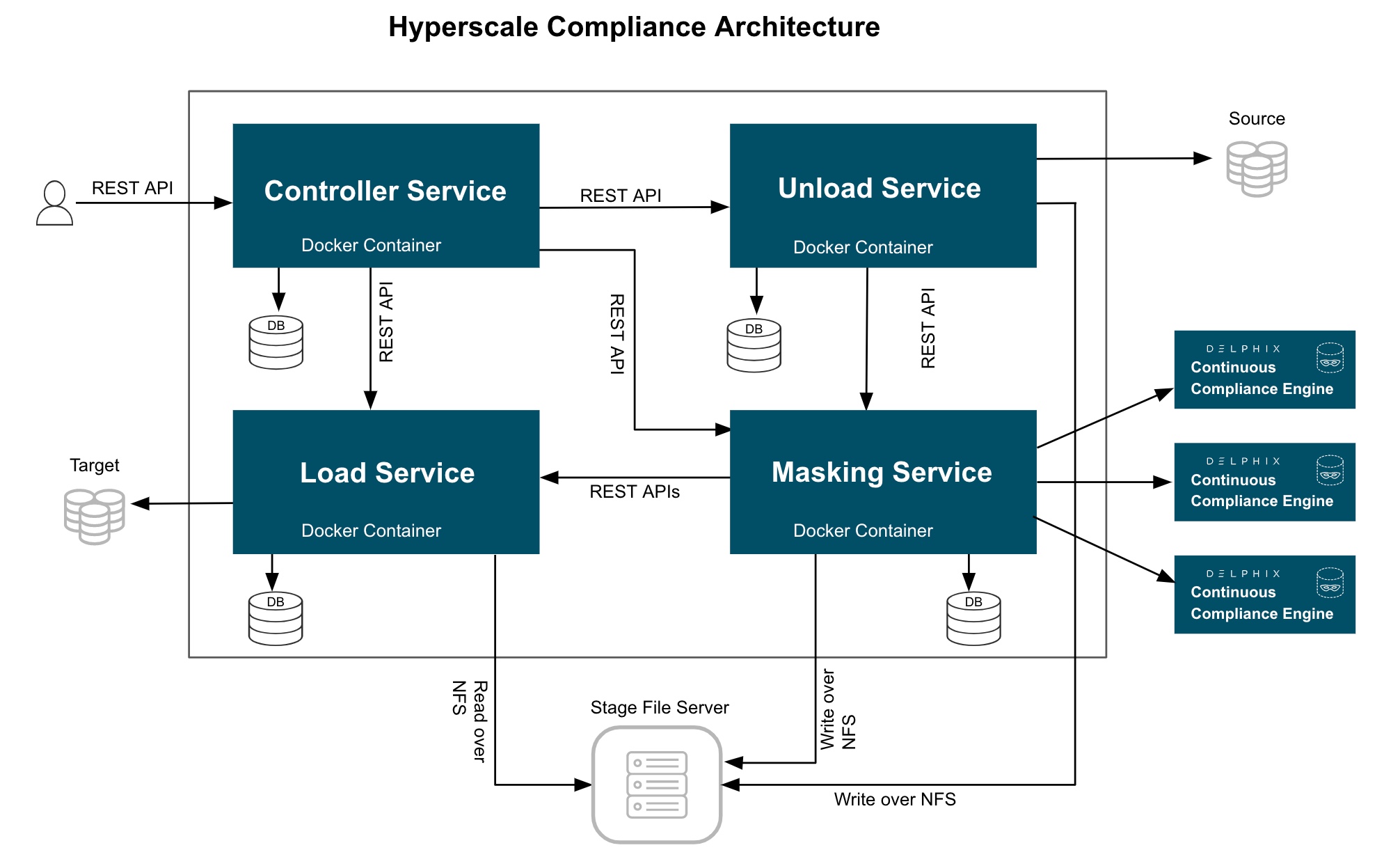
Controller Service
The following are the main functions of a controller service:
- Exposes user accessible API.
- Once controller service receives user requests (for example, register engine, create dataset, create connector, create Job, etc.), it will split the request and sends request for further processing to downstream services (Unload, Masking, Load) and once response is received from downstream service, the same will be processed by controller service and returned to the user.
- Controller service accepts request job execution from the user and invokes the job execution process by invoking unload service asynchronously.
- Controller service will keep polling data job execution data from downstream service until execution completes.
- Controller service will also determine the status of job execution and store execution data in the database.
- Controller service allows you to restart a failed (Failed during File Loader, Post Load) execution
Unload Service
The following are the main functions of a unload service:
- Exposes APIs that are accessible to internal services only.
- Unload service exposes required APIs that helps caller (controller service) to create required inputs (source info, dataset, etc.) for job execution.
- Unload service exposes an API to trigger unload from source datasource. As part of the unload process, it performs the following operations:
- Reads metadata of source datasource (e.g. number of rows in a source file/table) and stores that in the unload service database.
- Reads data from source datasource parallelly (by starting multiple parallel processes for each source entity like tables in case of relational database ) and stores this data in
.csvfiles. - Once data is loaded into one
.csvfile, unload service triggers masking service to start masking process for that*.csvfile.
- For running execution, Unload service maintains metadata data (number of rows processed, table/file names processed, etc.) in its database. This data can be retrieved by calling an API.
- Once execution completes execution data in the database and file system gets cleaned by invoking corresponding API.
Masking Service
The following are the main functions of a masking service:
- Exposes APIs that are accessible to internal services only.
- Masking services expose required APIs that help the caller (controller service) to create required inputs (Continuous Compliance engine info, dataset, job, etc.) for job execution.
- Masking service exposes an API to trigger the masking process. As part of masking process, it performs the following operations after receiving masking request from unload service for a csv file:
- Split the csv file based on the split size.
- Based on Intelligent load balancing, create and start jobs for splitted files on Continuous Compliance Engines (based on capacity of Continuous Compliance Engines associated with the hyperscale job).
- Monitor Continuous Compliance Engine jobs triggered in the previous step.
- Once monitoring determines that a Continuous Compliance Engine has successfully masked the file, send an async request to the load service (to load data into target datasource) for that masked file.
- For running execution, Masking service maintains metadata data (number of rows processed, table/file names processed, etc.) in its database. This data can be retrieved by calling an API.
- Once execution completes execution data in the database and file system gets cleaned by invoking corresponding API.
Load Service
The following are the main functions of a Load service:
- Exposes APIs that are accessible to internal services only.
- Load service exposes required APIs that helps the caller to create required inputs (target datasource info, dataset, job, etc.) for job execution.
- Load service exposes an API to trigger the Load process. As part of Load process, it performs following operations after receiving a load request from masking service for a masked csv file:
- Perform preload step (for example, cleaning up target directory or disabling constraints/triggers/indexes). These may be performed once for an execution process (not for each request from masking service).
- Load masked files into target datasource.
- Once Loading for a masked is completed, the metadata for this “file load“ will be stored in the load service database.
- For running execution, Load service maintains metadata data (number of rows processed, table/file names processed, etc.) in its database. This data can be retrieved by calling an API.
- Once execution completes execution data in the database and file system gets cleaned by invoking the corresponding API.
- If Load service is for a datasource which requires post load steps (e.g. Oracle DB), then it will include post load steps which will be triggered by controller service once all files are successfully loaded into target data source.
- Load service also allows restarting for the post load step, if post load fails for an execution.